之前做 MOT 还是沿着 SOT 的思路,这篇文章对 MOT 有一个很深入且很有框架性的综述,以下对这篇文章做一个提炼,并加入一些自己的想法。
MOT 作为一个中层任务,是一些高层任务的基础,比如行人的 pose estimation,action recognition,behavior analysis,车辆的 state estimation。单目标跟踪(SOT)主要关注 appearance model 以及 motion model 的设计,解决尺度、旋转、光照等影响因素。而 MOT 包含两个任务:目标数量以及目标ID,这就要求 MOT 还需要解决其它问题:
- frequent occlusions
- initialization and termination of tracks
- similar appearance
- interactions among multiple objects
1. 问题描述
多目标跟踪实际上是多参数估计问题。给定图像序列\(\{I_1,I_2,...,I_t,...\}\),第\(t\)帧中目标个数为\(M_t\),第\(t\)帧中所有目标的状态表示为\(S_t=\{s_t^ 1,s_t^ 2,...,s_t^ {M_t}\}\),第\(i\)个目标的轨迹表示为\(s_{1:t}^ i=\{s_1^ i,s_2^ i,...,s_t^ i\}\),所有图像中所有目标的状态序列为\(S_{1:t}=\{S_1,S_2,...,S_t\}\)。相应的,所有图像中所有目标观测到的状态序列为\(O_{1:t}=\{O_1,O_2,...,O_t\}\)。多目标跟踪的优化目标是求解最优的各目标状态,即求解一个后验概率问题,\[ \widehat{S}_{1:t}=\mathop{\arg\max}_{S_{1:t}}P(S_{1:t}|O_{1:t})\] 这种形式有两种实现方法:
probabilistic inference
适合用于 online tracking 任务,Dynamic Model 为 \(P(S_t|S_{t-1})\),Observation Model 为 \(P(O_t|S_t)\),两步求解过程:
\(\circ\) Predict: \(P(S_t|O_{1:t-1})=\int P(S_t|S_{t-1})dS_{t-1}\)
\(\circ\) Update: \(P(S_t|O_{1:t}) \propto P(O_t|S_t)P(S_t|O_{1:t-1})\)deterministic optimization
适合用于 offline tracking 任务,直接利用多帧信息进行最优化求解。
2. 分类方法
initialization method
初始化方式分为:
\(\circ\) Detection-Based Tracking,优势明显,除了只能处理特定的目标类型;
\(\circ\) Detection-Free Tracking,能处理任何目标类型;processing mode
根据是否使用未来的观测,处理方式可分为:
\(\circ\) online tracking,适合在线任务,缺点是观测量会比较少;
\(\circ\) offline tracking,输出结果存在时延,理论上能获得全局最优解;type of output
根据问题求解方式输出是否存在随机性:
\(\circ\) probabilistic inference,概率性推断;
\(\circ\) deterministic inference,求解最大后验概率;自动驾驶等在线任务主要关注 Detection-Based,online tracking。
3. 框架
MOT 主要考虑两个问题:
- 目标在不同帧之间的相似性度量,即对appearance, motion, interaction, exclusion, occlusion的建模;
- 恢复出目标的ID,即 inference 过程;
3.1. Appearance Model
3.1.1. Visual Representation
视觉表达即目标的特征表示方式:
- local features
本质上是点特征,点特征由 corner+descriptor(角点+描述子) 组成。KLT(good features to track)在 SOT 中应用广泛,用它可以生成短轨迹,估计相机运动位姿,运动聚类等;Optical Flow也是一种局部特征,在数据关联之前也可用于将检测目标连接到短轨迹中去。 - region features
在一个块区域内提取特征,根据像素间作差的次数,可分为:- zero-order, color histogram & raw pixel template
- first-order, HOG & level-set formulation(?)
- up-to-second-order, Region covariance matrix
- others
其它特征本质上也需要 local 或 region 的方式提取,只是原始信息并不是灰度或彩图。如 depth,probabilistic occupancy map, gait feature.
Local features,比如颜色特征,在计算上比较高效,但是对遮挡,旋转比较敏感;Region features 里,HOG 对光照有一定的鲁棒性,但是对遮挡及形变效果较差;Region covariance matrix 更加鲁棒,但是需要更高的计算量;深度特征也比较有效,但是需要额外的获取深度信息的代价。
3.1.2. Statistical Measuring
有了目标的特征表示方式之后,就可以评价两个观察的目标的相似性。特征表示的线索(cue)可分为:
- single cue
因为只有一个线索,相似性(similarity)可以直接通过两个向量的距离转换得到。可以将距离指数化,高斯化。也可以将不相似度转为可能性,用协方差矩阵表示。 - multiple cues
多线索,即多种特征的融合,能极大提高鲁棒性,融合的策略有:- Boosting, 选取一系列的特征,用 boost 算法选取表达能力最强的特征;
- Concatenation, 各个特征直接在空间维度上串起来,形成一个 cue 的表达方式;
- Summation, 加权融合各个特征,形成一个 cue 的表达方式;
- Product, 各个特征相乘的方式,比如目标 \(s_0\) 的某个潜在匹配 \(s_1\) 的颜色,形状特征为 \(color\), \(shape\) 的概率为 \(p(color|s_0)\), \(p(shape|s_0)\), 假设特征独立,那么, \[p(s_1|s_0)=p(color, shape|s_0)=p(color|s_0)\cdot p(shape|s_0)\]
- Cascading, coarse-to-fine 的方式,逐步精细化搜索;
3.2. Motion Model
运动模型对关联两个 tracklets 比较管用,而 online tracking 任务,对输出的时延要求较高,所以其中一个 tracklet 可以任务就是当前帧与上一帧形成的轨迹,所以这里很难去计算两个 tracklets 的相似度。能看到的一个应用点就是,通过 motion model 模型,预测下一时刻目标的位置,作为一个线索项目。以下讨论的各模型主要是为了度量 tracklets 的相似性,从而做 tracklets 的匹配。
3.2.1. Linear
- Velocity Smoothness. N 帧 M 个目标轨迹: \(C_{dyn}=\sum_{t=1}^ {N-2}\sum_{i=1}^ {M}\parallel v_i^ t-v_i^ {t+1}\parallel^ 2\)
- Position Smoothness. \(G(p^ {tail}+v^ {tail}\Delta t-p^ {head}, \sum_p)\cdot G(p^ {head}-v^ {head}\Delta t-p^ {tail}, \sum_p)\)
- Acceleration Smoothness.
3.2.2. Non-linear
运动模型假设是非线性的,相似度计算还是按照以上高斯形式。引为中提到,非线性运动模型并不作为目标的惩罚因子,因为目标并不需要满足该模型,但是只要有目标满足,就降低惩罚系数。
3.3. Interaction Model
3.3.1. Social Force Models
- Individual Force
- fidelity, 目标不会改变它的目的地方向;
- constancy, 目标不会突然改变速度和方向;
- Group Force
- attraction, 目标间应该尽量靠近;
- repulsion, 目标间也得保留适当的距离;
- coherence, 同一个 group 里面的目标速度应该差不多;
3.3.2. Crowd Motion Pattern Models
当一个 group 比较密集的时候,单个目标的运动模型不太显著了,这时候群体的运动模型更加有效,可以用一些方法来构建群体运动模型。
3.4. Exclusion Model
3.4.1. Detection-level
同一帧两个检测量不能指向同一个目标。匹配 tracklets 时,可以将这一项作为惩罚项。不过目前的检测技术都做了 NMS,基本可以消除这种情况。
3.4.2. Trajectory-level
两个轨迹不能非常靠近。对于 online tracking 来说,就是 tracking 结果的两个量不能挨在一起,如果挨在一起,就说明有问题,比如遮挡,或跟丢。
3.5. Occlusion Handling
- Part-to-whole, 将目标分成栅格来处理;
- Hypothesize-and-test,
- Buffer-and-recover, 在遮挡产生前,记录一定量的观测,遮挡后恢复;
- Others
3.6. Inference
3.6.1. Probabilistic Inference
概率法只需要用到当前时刻之前的信息,所以适合用于 online tracking 任务。首先,如果假设一阶马尔科夫,当前目标的状态之依赖于前一时刻目标的状态,即 dynamic model: \[P(S_t|S_{1:t-1})=P(S_t|S_{t-1})\] 其次,观测是独立的,即当前目标的观测只由当前目标的状态决定,observation model: \[P(O_{1:t}|S_{1:t})=\prod_{i=1}^t P(O_t|S_t)\] dynamic model 对应的就是跟踪算法策略,observation model 是状态观测手段,包括检测方法。目标状态估计的迭代过程为:
- predict step
根据 dynamic model,由目标的上一状态预测当前状态的后验概率分布; - update step
根据 observation model,更新当前目标状态的后验概率分布;
状态估计的过程伴随着噪音等因素的影响,常用的概率推断模型有:
- Kalman filter
- Extended Kalman filter
- Particle filter
3.6.2. Deterministic Optimization
确定性优化法需要至少一个时间窗口的观测量,所以适合 offline tracking 任务。优化方法有:
- Bipartite graph matching
- Dynamic Programming
- Min-cost max-flow network flow
- Conditional random field
- MWIS(Maximum-weight independent set)
4. 评价方法
评价方法是非常重要的,一方面对算法系统进行调参优化,另一方面比较各个不同算法的优劣。评价方法 (evaluation) 包括评价指标 (metrics) 以及数据集 (datasets),多类别的数据集主要有:
评价指标可分为:
A. 检测指标
\(\lozenge\) 准确性(Accuracy)
- Recall & Precision
- False Alarme per Frame(FAF) rate, from paper
- False Positive Per Image(FPPI), from paper
- MODA(Multiple Object Detection Accuracy), 包含了 false positive & miss dets. from paper
\(\lozenge\) 精确性(Precision)
- MODP(Multiple Object Detection Precision), 衡量检测框与真值框的位置对齐程度;from paper
B. 跟踪指标
\(\lozenge\) 准确性(Accuracy)
\(\lozenge\) 精确性(Precision)
- MOTP(Multiple Object Tracking Precision), from paper
- TDE(Tracking Distance Error), from paper
- OSPA(optimal subpattern assignment), from paper
\(\lozenge\) 完整性(Completeness)
- MT, the numbers of Mostly Tracked, from paper
- PT, the numbers of Partly Tracked
- ML, the numbers of Mostly Lost
- FM, the numbers of Fragmentation
\(\lozenge\) 鲁棒性(Robustness)
- RS(Recover from Short-term occlusion), from paper
- RL(Recover from Long-term occlusion)
评价指标汇总: 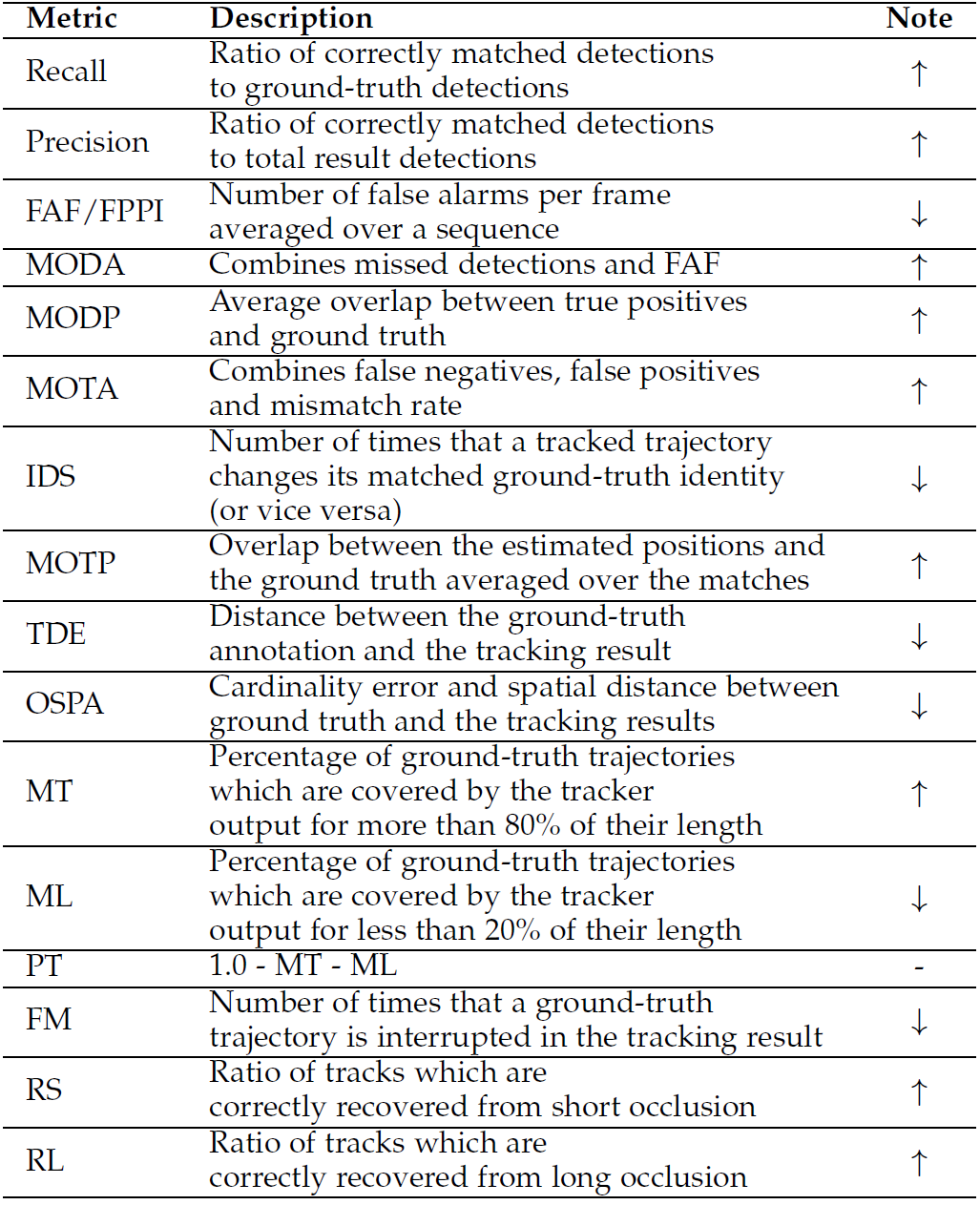
5. 总结
5.1. 还存在的问题
MOT 算法模块较多,参数也较复杂,但是最依赖于检测模块的性能,所以算法间比较性能时,需要注意按模块进行变量控制。
5.2. 未来研究方向
- MOT with video adaptation,检测模块式预先训练的,需要在线更新学习;
- MOT under multiple camera: \(\circ\) multiple views,不同视野相同场景信息的记录, \(\circ\) non-overlapping multi-camera,不同视野不同场景的 reidentification;
- Multiple 3D object tracking,能更准确预测位置,大小,更有效处理遮挡;
- MOT with scene understanding,拥挤场景,用场景理解来有效跟踪;
- MOT with deep learning
- MOT with other cv tasks,和其他任务融合,比如目标分割等;
